2025/11/28 更新
画像読み取り機能の操作方法
画像読み取り機能について
校正対象PDF上に文字情報がなく、非検出となった文言に対して確認をサポートする機能です。
利用条件
校正対象PDFが1ページであること
原稿Excelがアップロードされていること
機能の使い方
画像読み取り機能を利用する場合のタスク登録・確認作業は以下の流れで実施します。
1.タスク登録方法
校正タスク追加画面で「PDFの画像から文字を読み取る(β版)」のチェックボックスを選択することで有効化できます。
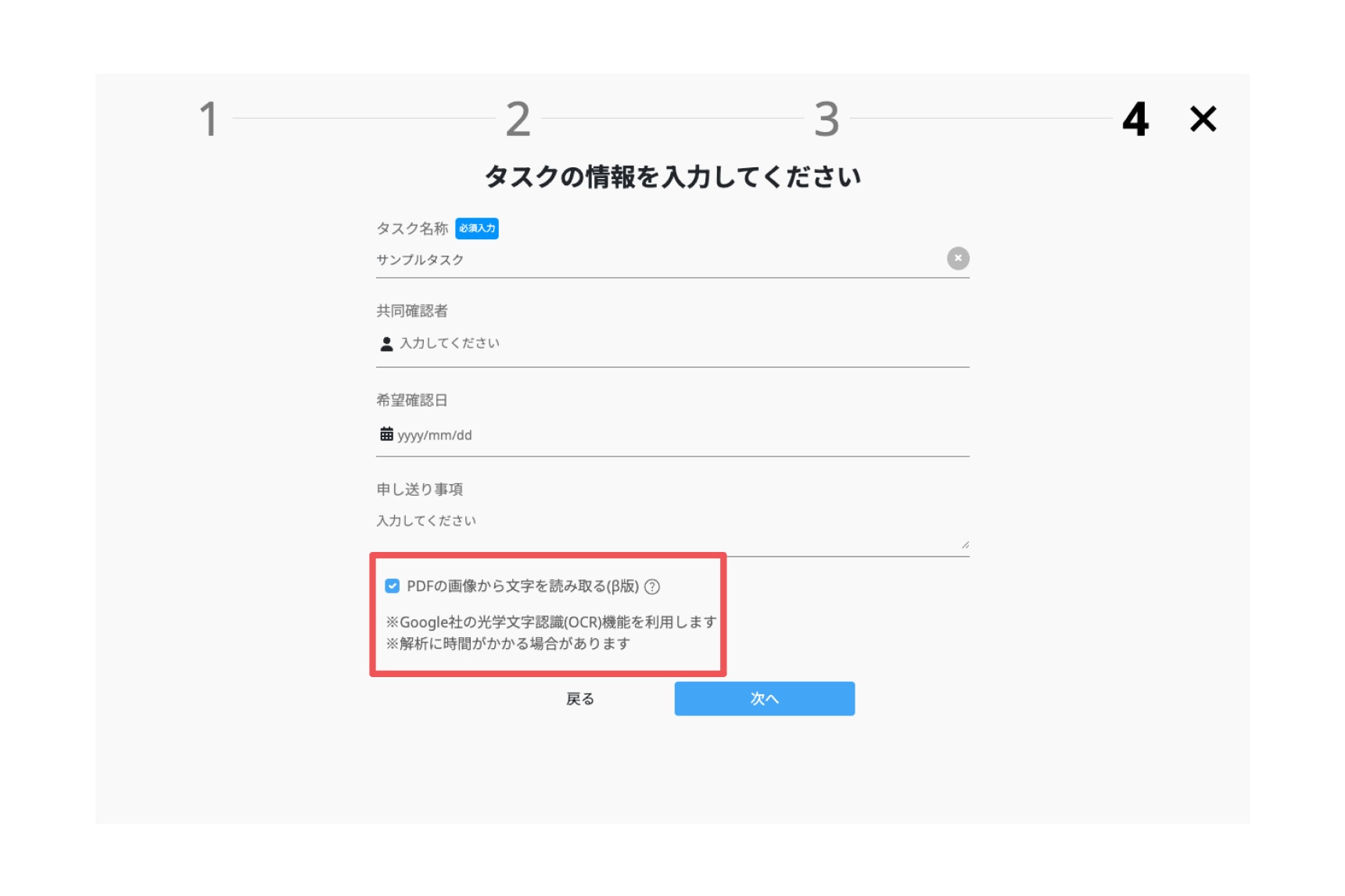
※校正タスク追加の方法は別記事「校正タスク追加の流れ」をご確認ください。
2.校正画面での表示
画像読み取りの結果、非検出になってしまった文言がPDF上で検出できれば、その箇所を校正画面上で示します。
付箋エリアでは「非検出」の付箋で画像から読み取った文字の内容と件数が表示されます(①)。
内容が部分的に一致した場合、差異のある文字は赤く表示されます(①')。
右側のチェックボックス(②)にチェックが入った状態となります。
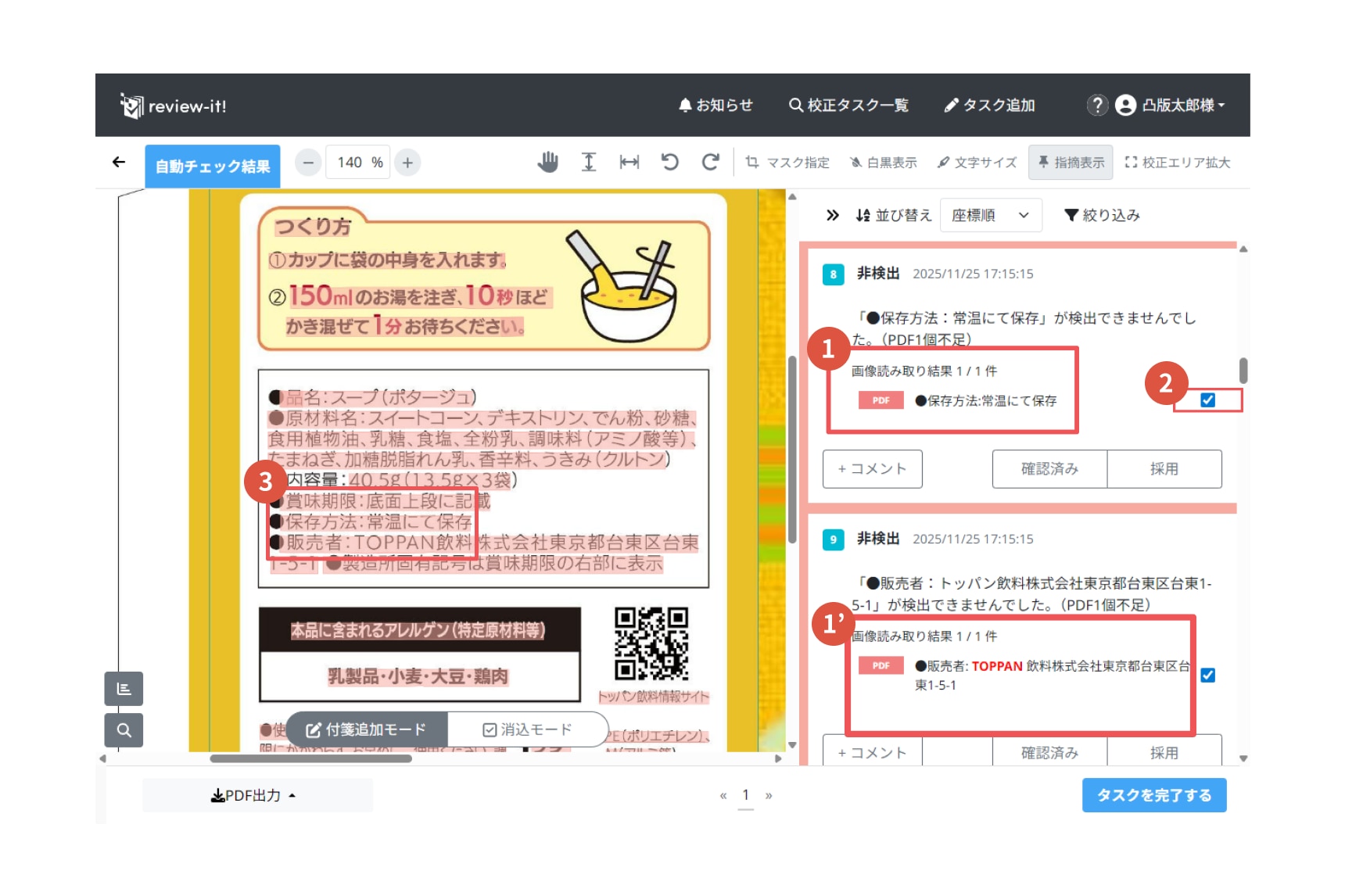
3.読み取り結果の確認
チェックが入っている箇所で非検出になってしまった文言がPDF上で検出できた場合、プレビューエリアで検出できた箇所に赤いマーカーが表示されます(③)。
マーカー表示の箇所を選択すると原稿Excelとの照合結果を確認することができます。
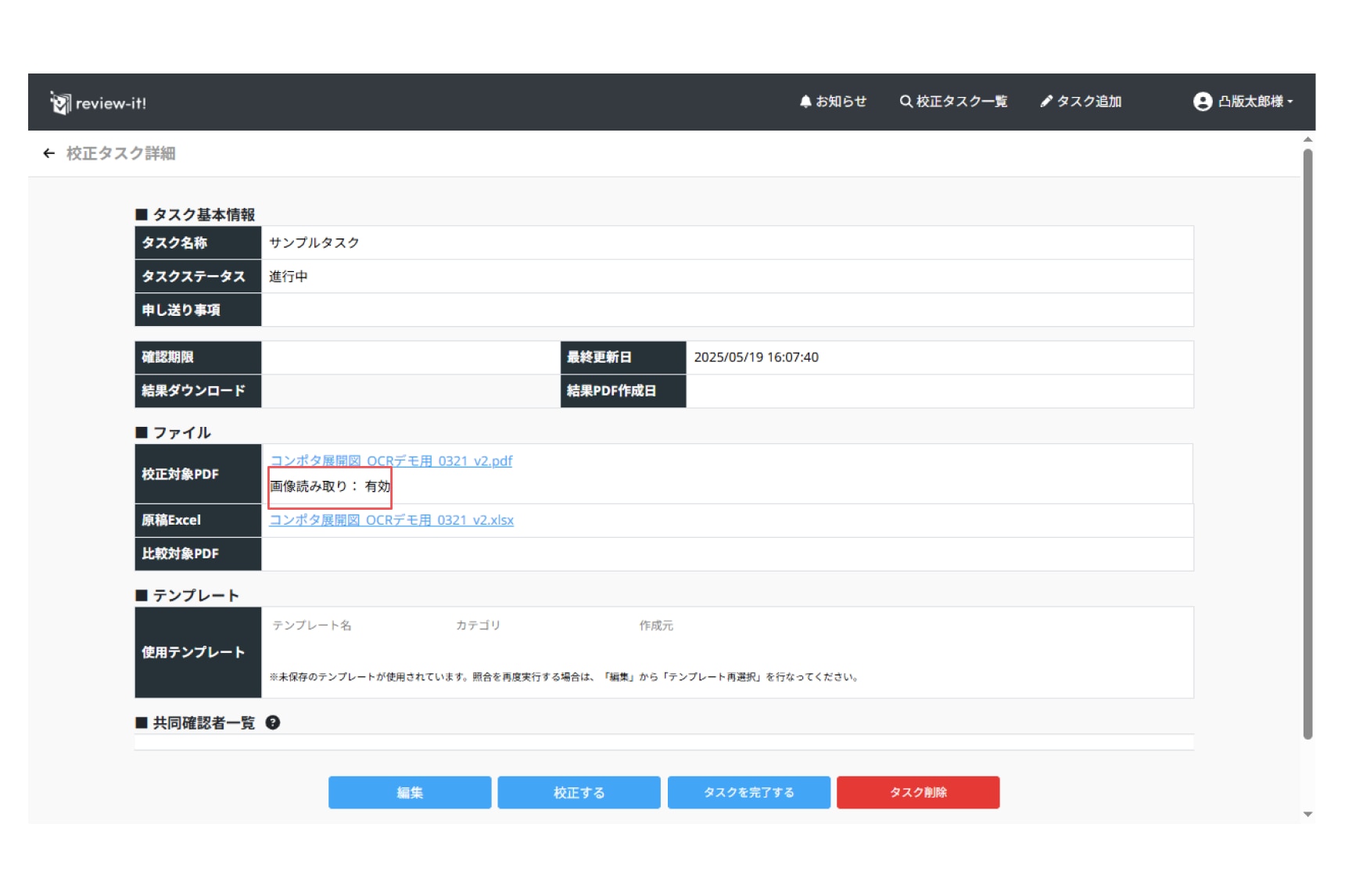
画像読み取り機能の確認方法
タスク詳細画面で校正対象PDFの表示をご確認ください。
画像読み取りが有効になっている場合「画像読み取り:有効」と表示されます。
トラブルシューティング
校正画面に「画像読み取りに失敗しました」と表示された場合は、画像読み取り機能に関するよくある質問をご確認ください。
解決しない場合はこちらからお問い合わせください。

© 2025 TOPPAN Digital Inc.